
Cos’è un data warehouse, come funziona, quali sono i principali vantaggi. Data warehouse, data lake e database: le differenze
Il data warehouse è un sistema di gestione dei dati che pareva ormai finito nel dimenticatoio delle tecnologie obsolete, accantonate a vantaggio di soluzioni di più agili nel trattare le enormi quantità di dati che le attuali applicazioni comportano. Invece, a causa di una serie di fattori più o meno fortuiti, i data warehouse, dopo una bella messa a nuovo, stanno vivendo una vera e propria seconda giovinezza, soprattutto grazie alla loro modernizzazione in cloud.
L’obiettivo di questa semplice lettura è quella di capire cosa sono i data warehouse, per comprendere al meglio i vantaggi che derivano dall’analisi dei dati utilizzando questi sistemi. Se un tempo venivano impiegati soprattutto per le attività di Business Intelligence sui dati strutturati, i data warehouse moderni sono in grado di gestire sempre più agevolmente i dati non strutturati, rendendoli disponibili anche per le operazioni di Business Analytics.

Cos’è un data warehouse
Il data warehouse è un sistema di sintesi e gestione che consente di rendere disponibili i dati per i processi analitici. È il caso delle attività che la Business Intelligence svolge per estrarre valore informativo dai dati stessi. La prima definizione di data warehouse deriva dalle parole di colui che viene ritenuto quale il suo inventore: “Data warehouse is a subject oriented, nonvolatile, integrated, time variant collection of data in support of management’s decisions”. L’obiettivo ultimo dei data warehouse sarebbe pertanto quello di consentire l’analisi dei dati per garantire decisioni meglio informate.
In ambito aziendale, il senso di questa articolata definizione è molto più semplice di quello che potrebbe sembrare. Nel contesto della trasformazione digitale, i dati sono diventati la principale risorsa in grado di generare valore aggiunto nei processi aziendali.
Tuttavia, all’origine, il dato è una risorsa grezza, che va estratta, pulita e raffinata, per poter essere lavorata dalle applicazioni in grado di trasformarla in una risorsa fruibile dagli utilizzatori finali, che siano gli addetti di una linea di produzione o i manager di una linea di business chiamati a dover prendere delle decisioni cruciali per le sorti dell’azienda.
Dove avvengono tutte queste operazioni sui dati? Sui sistemi in grado di gestirli, come i data warehouse.
Il data management di un’azienda moderna è un processo incredibilmente vario, sia in termini di obiettivi di business, sia per quanto riguarda le tecnologie utilizzate. Negli anni è avvenuta una notevole stratificazione degli archivi e delle fonti di dati impiegate per costituire i data set, al punto che molto spesso la prima cosa da fare, quando si ragiona nella prospettiva di dover analizzare i dati raccolti, è quella di evitare i data silos.
I data silos sono repository isolati, che vengono impiegati magari per singole occasioni, senza preoccuparsi di renderli comunicanti e compatibili con gli altri data set disponibili in azienda. Un data silos, anche qualora disponesse di dati di ottima qualità, risulta difficilmente accessibile, per cui la risorsa informativa in essa contenuta il più delle volte non viene valorizzata. Se un tempo si poteva chiudere un occhio, oggi una situazione del genere finisce per rivelarsi oltre modo penalizzante.
Un sistema come il data warehouse è stato concepito sin dall’origine per evitare questo tipo di problema, lavorando per ottenere un elevato livello di disponibilità dei dati ai fini dei processi analitici, che richiedono generalmente un elevato livello di interoperabilità.
Come funziona
Il data warehouse è un sistema in grado di collezionare i dati provenienti dalle operazioni aziendali. Esistono varie condizioni. L’azienda può infatti disporre di un unico data warehouse, disponibile per tutte le linee di business, oppure dedicare ad ogni reparto un sistema distinto, che prende nel caso il nome di data mart e consiste in un’unità più limitata, riservata esclusivamente ad una business unit.
Non esiste a priori una soluzione migliore di un’altra, nel preferire una gestione centralizzata ad un’articolazione decentralizzata in più unità di minore dimensione. Occorre analizzare nello specifico le esigenze di un’azienda nella gestione dei dati, in modo che possa supportare al meglio i processi analitici che ne richiedono l’impiego.
Per comprendere a grandi linee il funzionamento di un data warehouse è sufficiente considerare i suoi componenti fondamentali, la cui azione risulta piuttosto esplicita. Ci limitiamo a descriverne quattro:
1) Database server
Unità centralizzata per l’archiviazione e la gestione dei dati, disponibile on-premise o in cloud. A differenza dei comuni server dispongono di tecnologie specifiche per la gestione dei dati, come i database-in-memory, che utilizzano una memoria persistente, la cui comunicazione è molto più veloce rispetto alla tradizionale memoria di sistema.
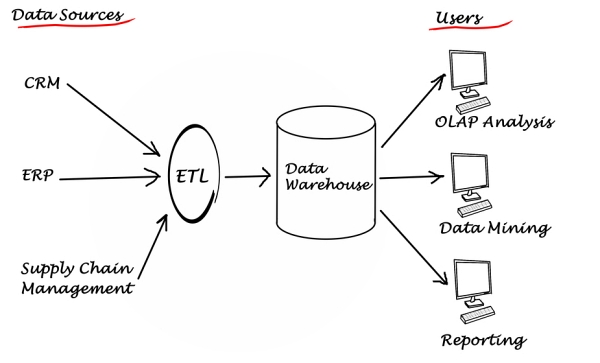
2) ETL (Extract, Transform, Load)
Consente di estrarre, trasformare e caricare i dati su un sistema di sintesi come il data warehouse. In sostanza è l’insieme delle azioni che costituisce la preparazione dei dati per l’analisi. Un processo ETL può avvenire sia in tempo reale che attraverso una pipeline automatizzata. Gli ETL di moderna concezione, disponibili in cloud, si avvalgono di funzionalità molto avanzate, che consentono un elevato livello di automatizzazione delle procedure sui dati, con logiche self-service e orientata a garantire un elevato livello di interoperabilità.
3) Metadati
Comprendono le informazioni necessarie per strutturare i dati per ottimizzare i tempi di esecuzione delle query e l’analisi dei dati. I metadati sono utili soprattutto per contestualizzare i dati in un sistema come il data warehouse, in modo da rendere più agevole la ricerca e l’accesso alle ai file ed ai loro contenuti.
4) Analisi dei dati
Nella sua concezione originale, il data warehouse era uno strumento privilegiato per i software di Business Intelligence. Una tradizione che si è mantenuta, ma al tempo stesso si è modernizzata ed ampliata notevolmente. I data warehouse di recente concezione sono ormai sistemi molto flessibili, capaci di gestire dati strutturati, non strutturati e semistrutturati, per renderli disponibili anche alle applicazioni di Business Analytics.
Attraverso questi componenti, il data warehouse è pertanto in grado di acquisire e preparare i dati per renderli disponibili ad analisi descrittive e predittive, utilizzando nel contesto anche strumenti di data visualization per creare i report e insight utili a informare e supportare i processi decisionali. Il percorso descritto è di per sé lineare, ma viene solitamente ripetuto un numero molto elevato di volte, in funzione del tipo di applicazione impiegata e della quantità e varietà dei dati coinvolti nei processi analitici.
Quali sono i vantaggi principali
Un data warehouse consente in primo luogo di fare ordine e consolidare i dati provenienti da molteplici fonti. Basterebbe questo aspetto, per delinearne la fondamentale importanza strategica e operativa in qualsiasi pipeline IT chiamata a supportare l’analisi dei dati.
In realtà, un data warehouse è molto di più di un eccellente sistema di gestione dei dati, in quanto consente di ottenere, direttamente e indirettamente, una serie di vantaggi molto ampia, in funzione del suo utilizzo:
Analisi dei dati storici e correnti
Il data warehouse è strutturato per archiviare e organizzare continuamente i dati provenienti dalle operazioni aziendali e da fonti esterne. La visibilità sul dato storico e sul dato corrente consente di effettuare analisi descrittive e predittive molto profonde, soprattutto se ci si avvale dei più moderni strumenti in grado di sfruttare tecniche di Machine Learning. Lo storico dei dati risulta infatti funzionale ai lavori della Business Intelligence e della Business Analytics;
Cloud e integrazione tecnologie Big Data & Analytics
Come preannunciato nel punto precedente, i data warehouse di moderna concezione, disponibili in cloud, sono in grado di implementare funzionalità analitiche avanzate grazie all’Intelligenza Artificiale e ad altre tecnologie capaci di rendere molto più profonda ed articolata la combinazione delle variabili, anche in presenza di enormi quantità di dati. La scalabilità delle risorse disponibili in cloud consente di affrontare con successo qualsiasi carico di lavoro richiesto dall’analisi dei dati.
Previa valutazione del budget disponibile, non è quindi necessario preoccuparsi degli eventuali limiti computazionali delle applicazioni sui data center locali. L’impiego di un data warehouse cloud native richiede con ogni probabilità un maggior sforzo in termini di data governance e costringe a fare i conti con eventuali problemi di latenza, ma presenta al tempo stesso una serie di vantaggi cruciali sul fronte dell’innovazione e della disponibilità di tecnologia di fatto esclusive per i servizi in cloud come il DWaaS (Data Warehouse as a Service);
Ottimizzazione delle query
I dati strutturati consentono di effettuare query veloci e precise anche in presenza di una grande quantità di dati, grazie all’elevata accessibilità dei sistemi data warehouse, progettati appositamente per questo scopo;
Data quality
Il processo ETL e le altre funzionalità di preparazione dei dati di cui dispone un data warehouse consentono di ottenere un’elevato livello di data quality, a tutto vantaggio dell’efficienza dei processi di analisi dei dati;
Decisioni migliori per il business
Dulcis in fundo, in un pur esemplificativa rassegna di vantaggi come quella che stiamo tentando, un’efficace analisi dei dati produce informazioni di maggior qualità, a tutto vantaggio del supporto decisionale per cui le attività nel contesto Big Data sono implementate in azienda. La disponibilità di report e insight in tempo reale, con la facilità di sintesi visuale che i più moderni software di data visualization consentono di ottenere, rappresenta un notevole valore aggiunto in quanto consente di interfacciare
L’architettura di un data warehouse
L’architettura di un data warehouse può essere descritta almeno da due punti di vista differenti, su base tipologica e in base ai livelli funzionali che possiede. A livello tipologico, esistono almeno quattro differenti architetture:
- Data warehouse semplice: i dati e i metadati sono archiviati in un unico repository centralizzato, dove sono caricati i dati provenienti dalle varie fonti;
- Data warehouse con gestione temporanea: rispetto ai sistemi semplici, hanno un’area predisposta per la preparazione distinta rispetto al repository, dove i dati vengono caricati dopo il processo ETL;
- Data warehouse sandbox: dotati di aree isolate rispetto al resto del sistema, per esplorare i dati e sperimentare metodi di analisi senza influire direttamente sulle funzionalità della parte in produzione;
- Data warehouse hub and spoke: è il caso dei data mart, dotati di zone intermedie tra il repository centrale e le applicazioni degli utenti finali, in modo da processare soltanto i dati necessari ad una singola divisione aziendale. Il layout hub and spoke sfrutta la decentralizzazione in unità di minore dimensione per snellire il carico di lavoro sui dati.
L’architettura di un data warehouse è al tempo stesso caratterizzata dai seguenti livelli funzionali:
- Front-End (layer di analisi): oltre all’interfaccia utente, comprende gli strumenti di analisi, reporting e data mining;
- Motore di analisi (layer semantico): comprende i server OLAP (OnLine Analytical Processing) e OLTP (OnLine Transactional Processing) che elaborano i dati per renderli disponibili alle applicazioni dei livelli superiori. Il motore di analisi costituisce ovviamente il cuore tecnologico del data warehouse, nonché l’elemento che lo distingue rispetto ad altri sistemi di sintesi dei dati;
- Database server (layer dei dati): è il vero e proprio magazzino dei dati, dove vengono caricati i dati preparati grazie al processo ETL. Il database server contiene inoltre i metadata e diverse applicazioni.
Gli elementi fin qui descritti costituiscono una sorta di denominatore comune per vari data warehouse attualmente disponibili in commercio. Le configurazioni possibili sono molte e vanno opportunamente valutate in funzione delle esigenze specifiche di ogni realtà aziendale.
Se ci mettessimo nei panni di un’azienda che vuole implementare un sistema di sintesi dei dati, la corretta base di partenza, ai fini di evitare un inutile sperpero di tempo e denaro, dovrebbe essere una consulenza di un system integrator o di un esperto di data governance, dotato di una significativa esperienza su casi studio reali, indispensabili per maturare quel know-how in fatto di dati per analizzare il contesto aziendale e proporre le architetture in grado di soddisfare gli obiettivi di business.
Non bisogna inoltre innamorarsi di una sola tecnologia, è importante aggiornarsi costantemente sulle principali soluzioni che il mercato offre. Gli scenari sono mutevoli e la disponibilità di una grande varietà tecnologica deve essere sfruttata a vantaggio dell’utente finale. Non avrebbe alcun senso precludersi delle opportunità soltanto perché un responsabile IT o un consulente non all’altezza conosce solo una soluzione, per giunta magari piuttosto obsoleta.
Anche se potrebbe sembrare il classico discorso paternalistico, si tratta soltanto di prendere atto che il problema, oggi, non è trovare la tecnologia per i dati, ma trovare quella più adatta in funzione delle proprie esigenze.
Data Warehouse e Data Lake
I data warehouse non sono certamente gli unici sistemi di sintesi dei dati, ma condividono tale scena con altre tecnologie. Una delle più note è senza dubbio il data lake, un repository di dati che vengono caricati senza essere stati preventivamente sottoposti ad una preparazione completa. Allo stato del caricamento, il dato disponibile sul data lake è infatti un dato ancora grezzo o proveniente da fonti esterne senza aver subito ulteriori lavorazioni rispetto al data set originale.
Il data lake si presta dunque al caricamento di enormi quantità di dati non strutturati, come i contenuti multimediali (audio/video), le registrazioni dei sistemi di videosorveglianza ed un’ampia tipologia di documenti non tabellari, in contenitori come i file pdf.
Per comprendere la differenza di trattamento che il dato subisce su un data warehouse e su un data lake è sufficiente tornare, ancora una volta, sul processo ETL, che consente la preparazione dei dati per renderli disponibili alle analisi.
Nel caso di un data lake, tale processo subisce una sostanziale variazione, in cui vengono invertite la fase di trasformazione e di caricamento dei dati. Gli ELT (Extract, Load, Transform) consentono di agire in maniera selettiva, soltanto sui dati che vengono richiesti dalle applicazioni rendendo molto più “economica” la pipeline rispetto al processo ETL, che carica nei repository dei data warehouse i dati solo quando sono stati preparati di tutto punto.
La differenza nell’archetipo che sussiste tra i data warehouse e i data lake, più che porli in una condizione alternativa, li rendono di fatto assolutamente complementari. È infatti possibile implementare una pipeline per cui nella fase iniziale si impiega un data lake, per archiviare enormi quantità di dati provenienti direttamente dalle applicazioni che li generano. Dopo aver capito cosa ci occorre analizzare, procediamo in maniera selettiva, preparando soltanto le i dati utili a soddisfare la nostra esigenza. A quel punto, possiamo caricarli su un data warehouse, dove renderli disponibili alle applicazioni di analisi dei dati.
Una pipeline organizzata in questo modo consente di sfruttare i vantaggi dei relativi sistemi: grandi quantità di dati con costi di storage contenuti, senza perdere l’efficienza nelle query e nell’analisi, che vengono svolte soltanto su una porzione dei dati archiviati.
Va inoltre precisato come i sistemi data warehouse, rispetto alla concezione che avevano negli anni Ottanta, si sono notevolmente evoluti, sia in termini di connettori, sia per quanto concerne le applicazioni integrate. Ciò è avvenuto per andare incontro alle esigenze dei clienti, che hanno iniziato a richiedere, oltre al supporto di dati strutturati di tipo tabellare, anche la possibilità di archiviare e poter gestire i dati non strutturati, oltre ai dati grezzi provenienti dai sistemi IoT.
La ragione di questa evoluzione è che gli utenti trovavano giustamente assurdo dover utilizzare più piattaforme per gestire tipologie di dati differenti. Al tempo stesso questo non vuole dire che i sistemi di data warehouse siano diventati dei data lake tutto fare, in quanto si sono limitati ad aggiungere dei layer funzionali a quelli di cui già disponevano.
I data warehouse moderni integrano anche funzionalità Big Data & Analytics basate su tecniche di Machine Learning, capaci di analizzare anche i dati non tabellari. Allo stesso modo, le applicazioni di Business Intelligence si sono notevolmente evolute soprattutto per quanto concerne la visualizzazione dei dati, sempre più potente, efficace graficamente e interattiva nei contenuti, per rendere le aziende sempre più data-driven.
Data warehouse e database: le differenze
La principale differenza tra i database e i data warehouse risiede sostanzialmente negli obiettivi per cui sono stati creati. Mentre i data warehouse, come abbiamo visto e precisato in più occasioni, sono stati implementati per rendere disponibili i dati per le query e le analisi richieste dalle applicazioni aziendali, i sistemi di database consentono di acquisire i dati delle varie linee di business, senza dover necessariamente contemplare il processo analitico.
In maniera un po’ brutale, ma concettualmente sincera, potremmo dunque definire il data warehouse quale un database la cui architettura dispone di elementi addizionali che consentono di supportare tutte le applicazioni di analisi dei dati.
Un data warehouse può infatti comprendere anche più database e ciò avviene anche grazie a certe differenze attitudinali tra i due sistemi di sintesi. I database prediligono l’acquisizione da un’unica origine di dati e sono ottimizzati per letture frequenti su blocchi di piccole dimensioni, mentre i data warehouse vengono spesso impiegati per acquisire da più origini e lavorare con grandi quantità di dati.



