Impiegato per gestire una grande quantità di informazioni, il database relazionale ha conosciuto un grande successo. Ecco le caratteristiche, le tipologie, i pregi (e anche i limiti)
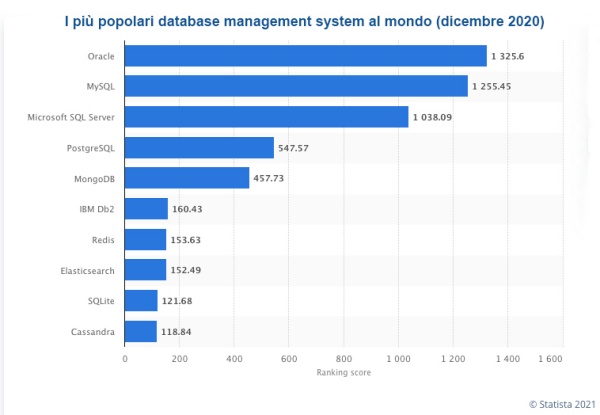
Un database relazionale organizza i dati in tabelle. Detto così sembra semplice, ma l’importanza che offre un sistema di archiviazione di questo tipo è confermata dal successo che ha incontrato dalla sua origine a oggi. Ideato dall’informatico Edgar Codd nel 1970, da allora è diventato il modello di database dominante per le applicazioni commerciali in tutto il mondo. Lo evidenzia bene il grafico di mercato Statista sui più popolari database management systems: nelle prime 6 posizioni ci sono solo Relational DBMS.
Perché sono così popolari? La miglior risposta la fornisce Sean Doherty, CFO di LogDna, in un articolo su Wired dedicato al futuro dei database: “Relational databases may not be hot or sexy but for your important data there is no substitute”. Tradotto in sintesi: i database relazionali possono anche non essere così “attraenti”, ma per i vostri dati importanti sono insostituibili.

Quando si hanno grandi quantità di informazioni da dover mettere in relazione non hanno avversari: non è un caso che la NASA lo abbia scelto per il suo HEASARC (High Energy Astrophysics Science Archive Research Center), l’archivio principale per le missioni della Agenzia spaziale americana e di altre agenzie che studiano la radiazione elettromagnetica da fenomeni cosmici estremamente energetici che vanno dai buchi neri al Big Bang. Ed è solo un esempio.
Cos’è un database relazionale
Per spiegare cosa sia questo sistema, è bene partire dal database, componente fondamentale di qualsiasi sistema informatico. Esso è un insieme di dati archiviati e memorizzati in un computer. Ogni programma utilizza o genera informazioni che devono essere memorizzate in modo affidabile e permanente. Questi sono di solito strutturati in un modo che possano essere facilmente accessibili. Un relational database fa parte di questa famiglia. È un archivio di dati strutturato in modo da razionalizzare la gestione e l’aggiornamento delle informazioni e da permettere lo svolgimento di ricerche complesse. Spesso, i dati in un database relazionale sono organizzati in tabelle. Una tabella è composta da righe e colonne. Le tabelle possono avere centinaia, migliaia, a volte anche milioni di righe, denominate record. Inoltre, possono anche contare su molte colonne (campo o attributo), che sono etichettate con un nome descrittivo (per esempio, età) e comprendono un tipo di dati specifico.
Una tabella di database è simile a un foglio di calcolo. Tuttavia, le relazioni che possono essere create tra le tabelle permettono a un database relazionale di immagazzinare in modo efficiente enormi quantità di dati e di recuperare efficacemente quelli selezionati.
Per poterlo creare, aggiornare e amministrare si usa un Relational Database Management System (RDBMS), programma che permette di creare, aggiornare e amministrare un database relazionale. La maggior parte dei RDBMS usa il linguaggio SQL per accedere al database. SQL (Structured Query Language) è un linguaggio utilizzato per comunicare con i dati memorizzati in un sistema di gestione specifica. La sintassi SQL è simile alla lingua inglese, il che la rende relativamente facile da scrivere, leggere e interpretare. Molti RDBMS usano SQL (e varianti) per accedere ai dati nelle tabelle. È l’elemento costante di tutti i tipi di database relazionali.
Ecco una breve descrizione degli RDBMS popolari:
- MySQL – È il più popolare database SQL open source. È tipicamente usato per lo sviluppo di applicazioni web, e spesso vi si accede usando PHP.
I principali vantaggi sono: la facilità d’uso, la relativa economicità, l’affidabilità (esiste dal 1995), e ha una grande comunità di sviluppatori che possono aiutare a rispondere alle domande.
Per contro, soffre di scarse prestazioni quando si scala, lo sviluppo open source è in ritardo da quando Oracle ha preso il controllo di MySQL, e non include alcune caratteristiche avanzate a cui gli sviluppatori possono essere abituati.
- PostgreSQL – Si tratta di un database SQL open source che non è controllato da nessuna società. È tipicamente usato per lo sviluppo di applicazioni web. PostgreSQL condivide molti degli stessi vantaggi di MySQL. È facile da usare, poco costoso, affidabile e ha una grande comunità di sviluppatori. Fornisce anche alcune caratteristiche aggiuntive come il supporto per le chiavi esterne senza richiedere una configurazione complessa. Lo svantaggio principale di questo sistema è che può essere più lento nelle prestazioni di altri database ed è anche leggermente meno popolare.
- Oracle DB – Questo RDBMS è particolarmente per grandi applicazioni, in particolare nel settore bancario. La maggior parte delle migliori banche del mondo eseguono applicazioni Oracle perché offre una potente combinazione di tecnologia e applicazioni aziendali complete e pre-integrate, incluse funzionalità essenziali costruite appositamente per le banche. Lo svantaggio principale dell’uso di Oracle è che non è gratuito da usare come i suoi concorrenti open source e può essere piuttosto costoso.
- SQL Server – È un DBMS relazionale prodotto da Microsoft. Al pari di Oracle DB, è molto usato dalle grandi realtà aziendali. Microsoft offre una versione entry-level gratuita chiamata Express, ma può diventare molto costosa quando si scala la propria applicazione.
- SQLite – Popolare database SQL open source, SQLite può memorizzare un intero database in un singolo file. Uno dei vantaggi più significativi che fornisce è che tutti i dati possono essere memorizzati localmente senza dover collegare il database ad un server. SQLite è una scelta popolare per i database nei telefoni cellulari, PDA, lettori MP3, set-top box e altri gadget elettronici. I corsi SQL su Codecademy usano SQLite.
- Db2 – è un database relazionale commercialmente supportato da IBM che ha sia una versione in cloud-hosted che una versione on-premises.
Vantaggi e svantaggi
Sono diversi i benefici offerti dall’impiego di database relazionali. Il principale è rappresentato dalla capacità di creare informazioni significative unendo le tabelle. Ciò permette di capire le relazioni tra i dati, o come le tabelle si collegano. Gli analisti possono ordinare i risultati per data, nome o qualsiasi colonna.
Un altro beneficio è la sua flessibilità. SQL ha il suo linguaggio integrato per la creazione di tabelle chiamato Data Definition Language (DDL). Esso permette di aggiungere nuove colonne, aggiungere nuove tabelle, rinominare relazioni e fare altri cambiamenti anche mentre il database è in esecuzione e mentre le query sono in corso. Ciò consente di cambiare lo schema o il modo in cui si modellano i dati.
Essi inoltre eliminano la ridondanza dei dati. Le informazioni per un singolo cliente appaiono in un solo posto: una singola voce nella tabella dei clienti. La tabella degli ordini ha solo bisogno di memorizzare un collegamento alla tabella dei clienti. La pratica di separare i dati per evitare la ridondanza è chiamata normalizzazione. I progettisti di database progressivi si assicurano che le tabelle si normalizzino durante il processo di progettazione.
I database relazionali sono transazionali: garantiscono che lo stato dell’intero sistema sia coerente in ogni momento. La maggior parte di essi offre facili opzioni di esportazione e importazione, rendendo il backup e il ripristino davvero semplici. Queste esportazioni possono avvenire anche mentre il database è in funzione, rendendo facile il ripristino in caso di guasto. Quelli moderni, basati sul cloud, possono fare un mirroring continuo, ovvero duplicare i dati su più dischi fissi, evitando la loro perdita in caso di ripristino.

Oltre ai benefici, i database relazionali presentano anche alcuni svantaggi. Il principale è il costo dell’impostazione e del mantenimento del sistema. Per impostare un database relazionale, occorre acquistare un software specifico ed è necessario contare su un programmatore per creare un database relazionale usando il linguaggio SQL e un amministratore dedicato a mantenere il database una volta costruito. Indipendentemente dai dati utilizzati, occorre importarli da altri, come file di testo o fogli di calcolo Excel. Non importa la dimensione della vostra azienda, se memorizzate informazioni legalmente confidenziali o protette nel vostro database come informazioni sanitarie, numeri di previdenza sociale o numeri di carte di credito, dovrete anche proteggere i dati da accessi non autorizzati per soddisfare gli standard normativi.
L’abbondanza di informazioni e la loro progressiva complessità delle informazioni rappresentano un altro svantaggio per i database relazionali. Essi sono fatti per organizzare i dati secondo caratteristiche comuni. Immagini complesse, numeri, disegni e prodotti multimediali sfidano una facile categorizzazione, portando la strada a un nuovo tipo di database chiamato sistemi di gestione di database relazionali a oggetti (ORDBMS). Essi sono progettati per gestire le applicazioni più complesse e hanno la capacità di essere scalabili.
Alcuni database relazionali presentano limiti sulla lunghezza dei campi. Quando viene progettato, occorre specificare la quantità di dati da poter inserire in un campo. Alcuni nomi o query di ricerca sono più corti del reale, e questo può portare alla loro perdita.
Infine, quelli più complessi possono portare a diventare “isole di informazioni” dove le informazioni non possono essere condivise facilmente da un grande sistema all’altro. Fare in modo che questi database “parlino” tra loro può rivelarsi un’impresa complessa e costosa.
Performance peggiori rispetto ai database NoSQL. Il modello di database relazionale ha requisiti molto rigidi in termini di coerenza dei dati che nelle transazioni vanno a discapito della velocità di scrittura.
I limiti dei classici sistemi relazionali sono messi in evidenza soprattutto nell’amministrare grandi quantità di dati nel contesto di big data analytics e dall’archiviazione di tipi astratti, dove si distinguono invece sistemi specializzati come i database a oggetto o i concetti sviluppati nell’ambito del movimento NoSQL. Va detto, però, che il modello di database relazionale è chiaro, matematicamente valido e ha alle spalle più di 40 anni di utilizzo pratico. Il che non è poco.
Come progettare un database relazionale
Un database ben progettato permette di fare due cose: eliminare la ridondanza dei dati e assicurarne l’integrità e l’accuratezza. I database sono di solito personalizzati per soddisfare una particolare applicazione. Non ci sono due applicazioni personalizzate uguali, e quindi non ci sono due database uguali. Tutto questo vale anche per i database relazionali la cui progettazione deve tenere conto di quattro importanti passi.
Il primo riguarda la necessità di definire lo scopo del database, che implica la necessità di raccogliere i requisiti e definire l’obiettivo del database.
Secondo passo: occorre raccogliere i dati, organizzarli in tabelle e specificare le chiavi primarie
Una volta deciso lo scopo del database, raccogliete i dati che devono essere memorizzati nel database.
Creare relazioni tra le tabelle è il terzo importante passo. La potenza del database relazionale sta, appunto, nelle relazioni che possono essere definite tra le tabelle. L’aspetto cruciale nella progettazione è, quindi, identificare le relazioni tra le tabelle.
Infine, occorre raffinare e normalizzare il progetto. Per esempio, aggiungere più colonne, creare una nuova tabella per i dati opzionali usando, per esempio, una relazione uno-a-uno (nella quale un record in una tabella è associato a un unico record in un’altra tabella), dividere una tabella grande in due tabelle più piccole.
Altri modelli di database
Il database relazionale è uno dei quattro tipi comuni di sistemi che si può usare per gestire i dati aziendali. Gli altri tre sono: database gerarchici, database reticolare, database orientati agli oggetti e NoSQL.
Il database gerarchico è un modello di database che somiglia a una struttura ad albero, simile a un’architettura di cartelle nel sistema informatico. Le relazioni tra i record sono predefinite in un rapporto “uno a uno”. Inoltre, Il modello gerarchico consente di rappresentare informazioni usando la relazione tra segmenti “padre” e segmenti “figli”: ogni padre può avere molti figli, ma ogni figlio può avere un solo padre.
Tale modello presenta due svantaggi: a causa della struttura ad albero dello schema logico, per ottenere relazioni di tipo molti-a-molti è necessario duplicare i dati. Per accedere ai dati occorre attraversare tutto l’albero partendo dalla radice fino al nodo interessato.
Anche il database reticolare ha una struttura gerarchica. Tuttavia, invece di usare una gerarchia ad albero con un solo genitore, questo modello supporta le relazioni molti a molti, poiché le tabelle figlio possono avere più di un genitore. A differenza di quello relazionale che si basa su gruppi di record, ne considera uno alla volta.
Infine, il modello di database orientato agli oggetti collega tra loro pacchetti che appartengono allo stesso gruppo: un set di dati viene associato con tutti i suoi attributi a un unico oggetto. In tal modo, tutte le informazioni sono direttamente disponibili. Così, invece di essere distribuiti in diverse tabelle, i dati sono disponibili insieme.
I NoSQL o database non relazionali, sono un’alternativa popolare ai database relazionali. Essi assumono una varietà di forme e permettono di memorizzare e manipolare grandi quantità di dati non strutturati e semi-strutturati.
Seppure esistano dalla fine degli anni Sessanta, il nome “NoSQL” è stato coniato solo all’inizio del Duemila, innescato dalle esigenze delle aziende del Web 2.0. Questo modello di database è sempre più utilizzato nella gestione dei big data e nelle applicazioni web in real time.


