
Le opportunità applicative di machine learning e deep learning sono in continua crescita. Ciò dimostra il grande valore dei due sottoinsiemi di Intelligenza Artificiale che hanno peculiarità e differenze tra loro
Machine learning e deep learning sono parte delle nostre vite. Proprio così: per comprendere l’importanza e la pervasività dei due sottoinsiemi dell’intelligenza artificiale basta pensare a quante applicazioni usate nel quotidiano che fanno uso di uno o dell’altro. Dallo smartphone ad Alexa, dall’auto a Netflix, dalla capacità dei motori di ricerca di fornirci i risultati migliori alle tecniche di diagnostica medica, sono veramente tanti gli esempi. Aggiungiamoci anche i robot, l’auto a guida autonoma, le previsioni meteo… Le aziende sono sempre più interessate a integrare soluzioni e tecniche di intelligenza artificiale: secondo quanto emerso da un’indagine Gartner, il 48% dei CIO hanno risposto di aver attuato o di avere in programma l’implementazione di tecnologie AI e di machine learning nei prossimi 12 mesi. La penetrazione di machine learning e deep learning è sempre più rapida: se McKinsey segnalava nel 2020, nel proprio report sull’AI, che solo il 16% degli intervistati affermava che le proprie aziende avevano portato il deep learning oltre la fase di sperimentazione, Zion Market Research ha previsto lo scorso maggio che il mercato globale del deep learning, stimato a poco più di 11 miliardi nel 2021 raggiungerà un fatturato di 80,7 miliardi dollari con un tasso di crescita del 38,3%.
Cosa motiva questo incremento? Le tecnologie avanzate, il maggior uso dell’AI, la crescita industriale e di un modello di lavoro a ritmo serrato rendono necessari strumenti di machine e deep learning, in quanto “la grande quantità di dati generati e necessari per lo sviluppo deve essere facilmente accessibile e curata in qualsiasi momento”.

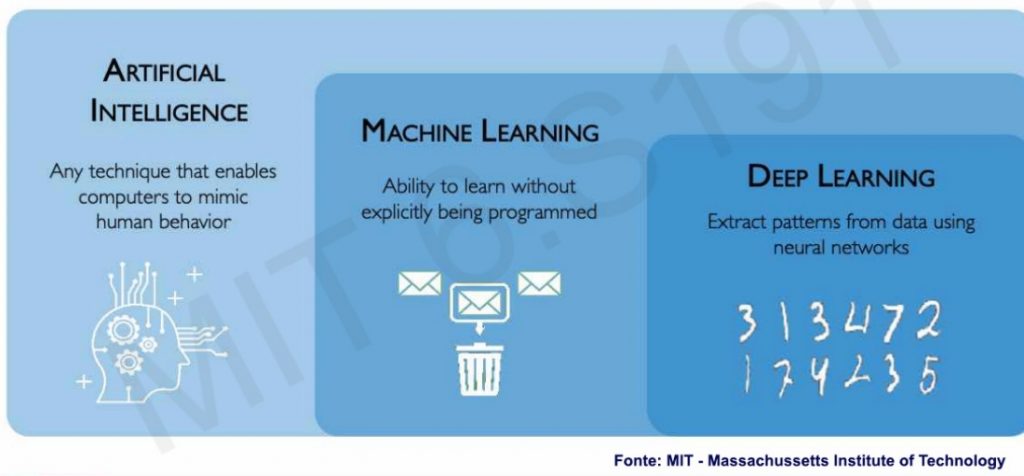
Machine Learning e Deep Learning: una definizione
Machine learning è un sottoinsieme dell’intelligenza artificiale, definito in senso lato come la capacità di una macchina di imitare il comportamento umano intelligente. I sistemi di intelligenza artificiale sono utilizzati per eseguire compiti complessi in modo simile a come gli esseri umani risolvono i problemi.
Deep learning è, a sua volta, un sottoinsieme del machine learning che si occupa di modelli basati su reti neurali a più livelli. È profondo proprio nel senso che i suoi modelli apprendono attraverso molti strati di trasformazioni.
ML studia come i sistemi informatici possano sfruttare l’esperienza (spesso i dati) per migliorare le prestazioni in compiti specifici. Combina idee di statistica, data mining e ottimizzazione. Spesso viene utilizzato come mezzo per implementare soluzioni di intelligenza artificiale.
DL è un elemento importante della data science, che comprende la statistica e la modellazione predittiva. È di grande utilità per gli scienziati dei dati che hanno il compito di raccogliere, analizzare e interpretare enormi quantità di dati, rendendo questo processo più veloce.
Machine learning
Una prima definizione di machine learning la si deve ad Arthur Samuel, autentico pioniere dell’AI. Nel 1959 coniò il termine apprendimento automatico come “campo di studio che dà ai computer la capacità di imparare senza essere esplicitamente programmati”.
Secondo Mike Shulman, docente al MIT Sloan School of Management e responsabile di ML presso Kensho (ora parte di S&P Global), specializzata in intelligenza artificiale per le comunità finanziarie e di intelligence degli Stati Uniti, ML consiste nel lasciare che i computer imparino a programmarsi da soli attraverso l’esperienza. Alla base del machine learning (come pure dell’AI e del deep learning) ci sono i dati: numeri, foto o testo, come transazioni bancarie, immagini… Essi vengono raccolti e preparati per essere utilizzati come dati di addestramento, ovvero le informazioni su cui verrà allenato il modello di apprendimento automatico. Più dati ci sono, migliore è il programma.
Esistono tre sottocategorie di ML: supervisionati, non supervisionati, per rinforzo. I primi, ovvero i supervised machine learning sono addestrati con serie di dati etichettati che consentono ai modelli di imparare e diventare più precisi nel tempo. Sono attualmente i più utilizzati.
Nel caso dell’unsupervised machine learning, un programma cerca modelli nei dati non etichettati. L’apprendimento automatico non supervisionato può trovare schemi o tendenze che non vengono esplicitamente cercati. Un esempio applicativo potrebbe riguardare l’impiego dei dati delle vendite online: grazie al UML è possibile identificare i diversi tipi di clienti che effettuano acquisti.
Il reinforcement machine learning addestra le macchine, attraverso prove ed errori, a intraprendere l’azione migliore stabilendo un sistema di ricompense. L’apprendimento per rinforzo può “allenare” i modelli a giocare o i veicoli autonomi a guidare dicendo alla macchina quando ha preso le decisioni giuste, aiutandola così ad apprendere nel tempo le azioni da svolgere.
Inoltre ML è associato anche a diversi altri sotto campi dell’intelligenza artificiale. C’è il Natural language processing, ambitonel quale le macchine imparano a comprendere il linguaggio naturale parlato e scritto dagli esseri umani, invece dei dati e dei numeri normalmente utilizzati per programmare i computer. Ci sono poi le neural network, le reti neurali, classe specifica di algoritmi di machine learning comunemente utilizzati. Sono composte da nodi, connessi l’uno all’altro: ognuno elabora gli input e produce un output che viene inviato ad altri neuroni. I dati etichettati si muovono attraverso i nodi e ognuno svolge una funzione diversa.
Infine, ci sono le deep learning network, reti neurali profonde, a più strati, in grado di elaborare grandi quantità di dati e di determinare il “peso” di ogni collegamento nella rete.
Deep learning
L’apprendimento profondo si avvale di strati di elaborazione delle informazioni, ognuno dei quali apprende gradualmente rappresentazioni sempre più complesse dei dati. È attualmente l’architettura AI più sofisticata a oggi sviluppata.
Deep learning è stato concepito sulla base della comprensione umana delle reti neurali. L’idea di costruire un’intelligenza artificiale basata sulle reti neurali esiste fin dagli anni Ottanta del XX secolo, ma è stato solo dal 2012 fa che ha preso piede. Proprio come l’apprendimento automatico deve la sua fioritura alla grande quantità di dati prodotti: la sua adozione sempre più sensibile è motivata alle potenze di calcolo molto più economiche e disponibili.
Oggi è utilizzato in tutti i settori e ha mostrato una forte domanda negli ultimi dieci anni. I fattori chiave che hanno portato alla crescita di questo mercato sono il miglioramento della potenza di calcolo, la diminuzione del costo dell’hardware e la crescente adozione di tecnologie cloud.
Le differenze tra Machine Learning e Deep Learning
La prima differenza da segnalare è tra intelligenza artificiale e machine learning. Quest’ultimo ha segnato una svolta nello sviluppo dell’AI. Prima del ML si cercava di insegnare ai computer tutti i dettagli di ogni decisione che dovevano prendere. In questo modo il processo era completamente visibile e l’algoritmo poteva occuparsi di molti scenari complessi. Tuttavia ci sono cose indefinibili con algoritmi basati su regole: per esempio, il riconoscimento dei volti. Un sistema rule-based dovrebbe rilevare forme diverse come i cerchi, per esempio. Machine learning adotta un approccio che, come detto, lascia che le macchine imparino da sole, ingerendo grandi quantità di dati e rilevando modelli. Molti algoritmi di apprendimento automatico utilizzano formule statistiche e grandi dati per funzionare. Arriva poi il deep learning: anche in questo caso al centro dell’apprendimento c’è l’intenzione di lasciare che la macchina impari dai dati. Ma DL è stato sviluppato sulla base della comprensione umana delle reti neurali. Proprio come l’apprendimento automatico deve la sua fioritura alla grande quantità di dati che abbiamo prodotto, ma quello profondo ha permesso di ottenere risultati molto più intelligenti di quelli originariamente possibili con quello automatico.
È un tipo di apprendimento automatico che utilizza reti neurali complesse per replicare l’intelligenza umana. Esso richiede in genere un hardware più avanzato per essere eseguito rispetto all’apprendimento automatico. Le GPU di fascia alta sono utili in questo caso, così come l’accesso a grandi quantità di energia. I modelli di deep learning sono in grado di apprendere in modo più rapido e autonomo rispetto ai modelli di ML e possono utilizzare meglio grandi insiemi di dati. Le applicazioni che impiegano tecniche di DL possono includere sistemi di riconoscimento facciale oppure le auto a guida autonoma.
La caratteristica forse più significativa dei metodi di deep learning è l’addestramento end-to-end. In altre parole, piuttosto che assemblare un sistema basato su componenti che vengono messi a punto singolarmente, si costruisce il sistema e poi si mettono a punto le loro prestazioni in modo congiunto.
Applicazioni
Machine learning e deep learning hanno vaste opportunità applicative. Nel primo caso, rientra il riconoscimento vocale, utilizzato negli smartphone, i filtri anti-spam, i motori di ricerca, ma è anche abilitatore della business intelligence, della targetizzazione delle email, della migliore determinazione del merito creditizio, fino a comprendere applicazioni utili in medicina e in agricoltura.
Per quanto riguarda il deep learning, i campi applicativi anche in questo caso sono molteplici. Dalla cybersecurity all’assistenza clienti mediante chatbot alla medicina: in quest’ultimo caso, il DL è stato ed è utile nel caso del rilevamento di Covid-19 a partire dall’analisi radiografica.
Un recente e interessante caso applicativo di DL è finalizzato alla scoperta di nuovi tipi di leghe, chiamate leghe ad alta entropia, classe di materiali candidati a superare le superleghe per applicazioni estreme. Il team di ricerca, coordinato da Wei Chen, professore associato di scienza e ingegneria dei materiali presso l’Illinois Institute of Technology ha raccolto un grande set di dati e applicato un’architettura Deep Sets, un’architettura avanzata di deep learning che genera modelli predittivi per le proprietà di nuove leghe ad alta entropia. Per elaborare si sono serviti del supercomputer Stampede2 del Texas Advanced Computing Center (classificato al 47° posto tra i 500 HPC più potenti al mondo). Grazie al nuovo modello di apprendimento e previsto le proprietà di oltre 370mila composizioni di leghe ad alta entropia.


