Cos’è il serverless computing, di che tipo di architettura si tratta, quali sono i vantaggi e quali gli ambiti applicativi
Il termine “serverless” fa immediatamente pensare a una struttura “senza server”, come vorrebbe la traduzione letterale.
In realtà, invece, a dispetto del suo significato, il nome rimanda a un modello di cloud che consente di creare e di eseguire applicazioni senza entrare in contatto con il server sottostante.

Si tratta, dunque, di un ambiente cloud in cui il server è comunque presente, ma dove le operazioni di provisioning, scalabilità e gestione sono demandate al fornitore del servizio.
Vediamo insieme di quale tecnologia si tratta e quali vantaggi e ambiti applicativi presenta.
Cos’è il serverless computing: una definizione
Un modello di cloud in cui gli sviluppatori creano ed eseguono applicazioni senza dover gestire i server, in quanto le attività relative alla loro manutenzione e alla loro scalabilità fanno capo al provider dei servizi cloud: è questo il serverless computing, detto anche FaaS – Function as a Service.
Si tratta di un paradigma diverso rispetto agli altri modelli di cloud computing, dal momento che il provider – come accennato – è responsabile della gestione dell’infrastruttura cloud, nonché della scalabilità delle app.
Al contrario, in un approccio di cloud computing Infrastructure-as-a-Service (IaaS) standard, il provider di cloud pubblico viene pagato per i componenti server utilizzati per l’esecuzione delle applicazioni. Componenti che sono sempre attivi.

All’utente spetta la responsabilità di elevare la capacità del server nelle fasi caratterizzate da picchi di domanda e, per converso, di ridurla quando non è più necessaria.
E l’infrastruttura cloud necessaria all’esecuzione di una data applicazione rimane attiva anche quando quest’ultima non è in uso.
Diversa cosa accade nell’ambito di un’architettura serverless, dove le applicazioni vengono avviate solo quando occorre.
Nel dettaglio, nel momento in cui un evento attiva l’esecuzione del codice, il provider di cloud pubblico assegna le risorse per quel codice e l’utente paga il servizio solo fino alla fine dell’esecuzione.
L’unica sfida, per l’utente, è integrare il proprio software – o la propria logica – nelle strutture cloud noleggiate. Il richiamo di queste funzioni si attiva in modo asincrono (tramite eventi) o in modo sincrono, ossia in base al classico modello client-server.
Nel primo caso (asincrono) si ha il vantaggio di impedire un accoppiamento eccessivo delle singole funzioni e di mantenere basso il fabbisogno di risorse durante l’esecuzione del programma.
Nella variante classica (sincrona), il client deve sempre inviare una richiesta separata al server, per richiamare una funzione corrispondente per la creazione della miniatura.
Questo schema, oltre agli intuibili vantaggi sotto il profilo dei costi, evita agli sviluppatori quelle attività di routine necessarie ad assicurare la scalabilità delle applicazioni, oltre alle operazioni per mezzo delle quali il server viene predisposto per essere utilizzato.
In sintesi, il serverless computing permette di demandare al provider di servizi cloud la gestione del sistema operativo e del file system, così come l’applicazione delle patch di sicurezza, la gestione della scalabilità, la registrazione e il monitoraggio.
Inoltre, nelle soluzioni serverless il provider di servizi cloud esegue i server fisici e ne destina le risorse per conto dell’utente, il quale può eseguire il deployment del codice direttamente nell’ambiente di produzione.
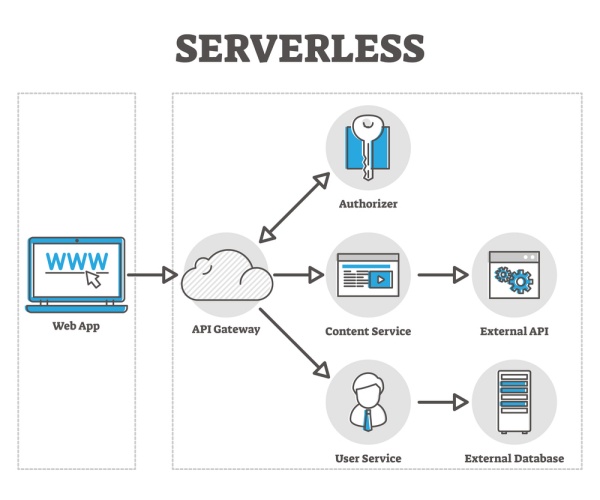
Panoramica dell’architettura Serveless
Un’architettura serverless, anche nota come architettura basata su funzioni, è un paradigma di progettazione di software in cui le applicazioni vengono sviluppate e gestite senza la necessità di mantenere server fisici o virtuali. Questo modello si affida a servizi cloud che eseguono codice in risposta a eventi, gestiscono l’allocazione automatica delle risorse, e scalano automaticamente per adattarsi al carico di lavoro. Di seguito forniamo uno schema concettuale di base di un’architettura serverless:
- Eventi (Triggers): L’esecuzione delle funzioni serverless è innescata da eventi specifici. Questi eventi possono essere richieste HTTP da un frontend web, messaggi da un sistema di coda, modifiche a un database, caricamenti di file su un bucket di storage, o timer preimpostati.
- Provider Cloud Serverless: Il fulcro dell’architettura serverless è il provider cloud, come AWS Lambda, Azure Functions, o Google Cloud Functions. Questi servizi eseguono il codice delle funzioni in risposta agli eventi, senza che lo sviluppatore debba gestire esplicitamente i server.
- Funzioni Serverless: Sono porzioni di codice stateless che eseguono una specifica logica di business in risposta agli eventi. Queste funzioni sono indipendenti, possono essere scalate automaticamente dal provider cloud, e lo sviluppatore paga solo per il tempo di esecuzione.
- Servizi di Backend: Le funzioni serverless spesso interagiscono con vari servizi di backend come database NoSQL (ad es., DynamoDB, CosmosDB), servizi di autenticazione (ad es., Cognito, Azure Active Directory), servizi di messaggistica (ad es., SNS, Queue), e storage (ad es., S3, Azure Blob Storage). Questi servizi sono gestiti dal provider cloud e integrati facilmente con le funzioni.
- API Gateway: Un API Gateway funge da interfaccia tra le funzioni serverless e i client esterni, esponendo le funzioni attraverso endpoint HTTP. Gestisce la routing delle richieste, l’autenticazione, la gestione del traffico, e può trasformare le richieste e le risposte.
- Frontend: Anche se non è parte dell’architettura serverless in senso stretto, le applicazioni moderne includono spesso un frontend (web o mobile) che interagisce con le funzioni serverless tramite l’API Gateway. Il frontend può essere ospitato staticamente su servizi cloud come AWS S3 con Amazon CloudFront o Azure Blob Storage con Azure CDN.
- Sicurezza e Compliance: I provider serverless offrono strumenti e configurazioni per garantire la sicurezza e la conformità delle applicazioni, incluse le politiche IAM, le reti virtuali, e le funzionalità di criptografia.
- Monitoraggio e Logging: I servizi serverless integrano capacità di monitoraggio e logging per tracciare l’esecuzione delle funzioni, le metriche di performance, e per diagnosticare problemi. Servizi come AWS CloudWatch o Azure Monitor sono comunemente utilizzati.
L’architettura serverless permette agli sviluppatori di concentrarsi sulla logica di business piuttosto che sulla gestione dell’infrastruttura, accelerando lo sviluppo e riducendo i costi operativi. Tuttavia, richiede un’attenta pianificazione per gestire i pattern di scalabilità, la latenza di avvio a freddo, e le dipendenze tra servizi.
Vantaggi del serverless computing
Un’architettura serverless offre numerosi vantaggi, sia in termini di sviluppo e gestione delle applicazioni che dal punto di vista economico. Ecco alcuni dei benefici principali:
Riduzione dei costi operativi
Non è necessario gestire o mantenere server fisici o virtuali, il che riduce significativamente i costi associati all’hardware, all’energia elettrica, e alla manutenzione.
Scalabilità automatica
Le risorse vengono automaticamente scalate dal provider cloud in base alla domanda, assicurando che l’applicazione possa gestire picchi di traffico senza la necessità di intervento manuale o pianificazione preventiva.
Pagamento per l’uso
Con il modello di fatturazione basato sull’utilizzo effettivo, si paga solo per il tempo di esecuzione del codice e non per le risorse idle. Questo può portare a un risparmio significativo, soprattutto per applicazioni con traffico variabile.
Tempo di messa sul mercato ridotto
L’architettura serverless permette agli sviluppatori di concentrarsi sulla logica di business senza preoccuparsi dell’infrastruttura sottostante, accelerando lo sviluppo e il rilascio di nuove funzionalità.
Manutenzione e gestione dell’infrastruttura ridotte
Il provider cloud si occupa della manutenzione dell’infrastruttura, delle patch di sicurezza, e degli aggiornamenti del sistema operativo, riducendo il carico di lavoro dell’IT.
Flessibilità dello sviluppo
Le funzioni serverless possono essere scritte in diversi linguaggi di programmazione, offrendo agli sviluppatori la libertà di utilizzare il linguaggio più adatto per ogni servizio o componente.
Elevata disponibilità e affidabilità
I provider cloud garantiscono l’alta disponibilità e affidabilità delle funzioni serverless, implementando automaticamente strategie di failover e replica dei dati.
Sicurezza migliorata
Beneficiando delle politiche di sicurezza e conformità del provider cloud, le applicazioni serverless possono essere più sicure contro attacchi informatici e vulnerabilità, a patto che vengano seguite le migliori pratiche di sicurezza.
Semplificazione del deployment e del rollback
Gli strumenti forniti dai provider cloud facilitano il deployment e il rollback del codice, permettendo aggiornamenti rapidi e riducendo il rischio di downtime.
Ecosistema integrato
Le architetture serverless si integrano facilmente con altri servizi cloud, come database, sistemi di autenticazione, storage, e servizi di analisi, offrendo un’ampia gamma di strumenti per arricchire le applicazioni.
Innovazione facilitata
L’adozione di un’architettura serverless incoraggia l’esplorazione di nuovi modelli di sviluppo e la sperimentazione, grazie alla riduzione del rischio e dei costi iniziali.
Questi vantaggi rendono l’architettura serverless una scelta attrattiva per molte aziende e sviluppatori, particolarmente per progetti che richiedono flessibilità, scalabilità, e una gestione efficiente dei costi.
Svantaggi del serverless computing
Nonostante i numerosi vantaggi, un’architettura serverless presenta anche alcuni svantaggi e limitazioni che possono influenzare la decisione di adottarla per certi progetti o applicazioni. Ecco alcuni dei principali svantaggi:
Problemi di avvio a freddo
Le funzioni serverless possono subire ritardi nell’esecuzione quando vengono attivate dopo un periodo di inattività, noto come “cold start”. Questo può impattare negativamente le performance, specialmente per le applicazioni che richiedono tempi di risposta rapidi.
Limitazioni di tempo di esecuzione
Molti provider di servizi serverless impongono limiti al tempo di esecuzione delle funzioni, che potrebbe non essere adatto per operazioni lunghe o complesse.
Controllo e personalizzazione dell’ambiente di esecuzione limitati
Con l’architettura serverless, si ha meno controllo sull’ambiente di esecuzione rispetto agli ambienti server tradizionali. Questo può limitare le possibilità di personalizzazione e ottimizzazione per specifici requisiti di performance o sicurezza.
Dipendenza dal provider (Vendor Lock-in)
Utilizzando servizi e API specifici di un provider cloud, le applicazioni possono diventare fortemente dipendenti da quel provider, rendendo difficile la migrazione verso altri servizi cloud o soluzioni on-premise.
Complessità nell’architettura e nella gestione dello stato
Le applicazioni serverless spesso coinvolgono molteplici funzioni piccole e interconnesse, il che può aumentare la complessità dell’architettura. Inoltre, la gestione dello stato tra funzioni stateless può richiedere soluzioni aggiuntive come database esterni o store di stati.
Monitoraggio e debugging più complessi
Data la natura distribuita e modulare delle applicazioni serverless, il monitoraggio e il debugging possono risultare più complessi rispetto agli approcci tradizionali, richiedendo strumenti e pratiche specifiche.
Costi imprevedibili
Sebbene il modello di pagamento per l’uso possa ridurre i costi per molte applicazioni, la natura dinamica del traffico e dell’utilizzo delle risorse può portare a costi imprevedibili e potenzialmente elevati in caso di picchi di traffico inaspettati.
Limitazioni e vincoli delle risorse
I provider serverless impongono limiti alle risorse disponibili per ciascuna funzione, come memoria, tempo di CPU, e concorrenza. Questo può essere un vincolo per applicazioni che richiedono risorse intensive.
Sicurezza e compliance
Se da un lato i provider cloud offrono robusti strumenti di sicurezza, la responsabilità della configurazione sicura delle funzioni e dei servizi associati rimane degli sviluppatori. Inoltre, le questioni di compliance e la necessità di adottare pratiche di sicurezza specifiche possono richiedere attenzione aggiuntiva.
Complessità nella gestione delle dipendenze
Le funzioni serverless possono diventare complesse da gestire in termini di dipendenze esterne, soprattutto quando il numero di funzioni e le interdipendenze crescono.
Mentre l’architettura serverless può offrire significativi benefici in termini di efficienza, scalabilità e costi, è importante valutare attentamente questi svantaggi in relazione ai requisiti specifici del progetto per determinare se questa è la scelta giusta. Sempre meglio affidarsi a system integrator e service provider in grado di garantire la massima flessibilità e assistenza, in modo da evitare di incappare in criticità come quelle sopra elencate.
Casi d’uso ed esempi del serverless, gli ambiti applicativi
Il computing serverless si presta a una vasta gamma di casi d’uso e applicazioni, grazie alla sua flessibilità, scalabilità e modello di pagamento basato sull’utilizzo. Ecco alcuni esempi significativi di come può essere impiegato:
1. Applicazioni Web e Mobile
Le funzioni serverless possono gestire le richieste backend di applicazioni web e mobile, come l’autenticazione degli utenti, l’elaborazione di form, l’interazione con database e l’integrazione con API di terze parti. Ciò consente di costruire applicazioni scalabili e responsive senza la necessità di gestire un’infrastruttura server.
2. API RESTful e GraphQL
Il serverless è ideale per costruire e ospitare API RESTful e GraphQL che si scalano automaticamente per soddisfare la domanda e si ridimensionano a zero quando non sono in uso, ottimizzando i costi.
3. Elaborazione di File e Stream di Dati
Le funzioni serverless possono essere utilizzate per elaborare file caricati (ad esempio, ridimensionamento di immagini, analisi di documenti, conversione di formati) e per l’elaborazione in tempo reale di stream di dati, come i log di sistema o i feed di social media, per analytics, filtraggio, o trasformazioni.
4. Automazione e Orchestrazione
Automatizzare workflow di business, processi IT, e task di manutenzione, come il backup dei dati, il controllo di integrità dei sistemi, l’esecuzione di script di deployment e l’automazione dei processi di build/test.
5. Internet delle Cose (IoT)
Nelle architetture IoT, il serverless può gestire e processare in modo efficiente grandi volumi di dati generati dai dispositivi, facilitando l’analisi in tempo reale, l’aggregazione dei dati, e la risposta a eventi specifici.
6. Chatbot e Interfacce Conversazionali
Sviluppare chatbot e interfacce conversazionali che rispondono a input utente in tempo reale, interagendo con sistemi esterni per fornire informazioni, assistenza clienti, o funzionalità di e-commerce.
7. Big Data e Analytics
Eseguire analisi di big data e operazioni di elaborazione dati senza dover gestire l’infrastruttura sottostante. Questo include l’elaborazione di batch, la trasformazione dei dati, e l’analisi predittiva.
8. Siti Web Statici e Applicazioni Single-Page (SPA)
Ospitare siti web statici o SPA, utilizzando il serverless per gestire le richieste dinamiche, come l’invio di form o l’interazione con database, rendendo queste applicazioni più dinamiche e interattive.
9. Sistemi di Notifica
Implementare sistemi di notifica che inviano email, SMS, o notifiche push in base a determinati eventi o azioni degli utenti, scalando automaticamente in base alla domanda.
10. E-commerce Personalizzato
Creare esperienze di e-commerce personalizzate e scalabili, gestendo carrelli della spesa, pagamenti, elaborazione di ordini, e integrazioni con sistemi di gestione delle scorte, senza la necessità di una costosa infrastruttura server dedicata.
Questi esempi mostrano la versatilità del serverless computing, rendendolo adatto a una varietà di scenari di sviluppo. La chiave è la sua capacità di ridurre il carico di gestione dell’infrastruttura, permettendo agli sviluppatori di concentrarsi sulla creazione di valore e innovazione per i loro utenti.
Cosa riserva il futuro
Il serverless è un modello di servizio cloud che punta a semplificare l’approccio alla programmazione, liberando il programmatore da tutti quegli aspetti che esulano dalla scrittura del codice.
Il suo utilizzo ha avuto un rapido aumento negli ultimi tre anni, con un tasso di crescita del 700%, e ha tutte le carte in regola per rappresentare, in futuro, una delle principali leve di sviluppo in ambito IT.
Negli anni a venire – come evidenziato dagli analisti di Forrester, sempre nel Report Demystifying Serverless Computing – dobbiamo attenderci numerosi sviluppi, sia per quanto concerne le architetture di severless computing, sia per quanto riguarda i servizi resi disponibili dai fornitori.
Tra le novità attese, vi è la possibilità di soluzioni serverless in container standardizzati. Il che concederebbe agli sviluppatori più controllo e contribuirebbe a evitare rapporti di dipendenza col proprio fornitore.
Un altro miglioramento atteso riguarda, invece, il supporto nelle transazioni distribuite o gestite in blockchain. La blockchain – lo ricordiamo – si coniuga molto bene con le caratteristiche di storage, comunicazione ed elaborazione distribuita proprie del serverless computing, naturalmente a patto di possedere le funzioni per controllare l’integrità di tutte le transazioni.
Sempre secondo Forrester, il modo migliore, in futuro, per sperimentare il serverless computing sarà nell’ambito del public cloud. E, a tale proposito, consiglia di identificare le migliori offerte dei provider con cui si hanno già rapporti oppure di scegliere in base alla disponibilità dei supporti utili per la gestione eventi.
In vista dello sviluppo futuro delle procedure serverless, potrà, infine, essere vantaggioso inserire fin da subito le capacità di generare eventi nelle applicazioni già in sviluppo con modalità tradizionali.


